Ultralytics YOLO Foundations: Part 1
Tasks & Inference
2026-05-14
Image Classification Output Concept

The model outputs probs, a probability for every possible class:
| Class ID | Class Name | Probability |
|---|---|---|
| 0 | car | 0.95 |
| 1 | bus | 0.03 |
| 2 | person | 0.01 |
| … | … | … |
From probs to top1

Ultralytics pre-computes the answer for us:
probs: Raw probability array for all classes.probs.top1→0: Index of the highest-probability class.probs.top1conf→0.95: Its confidence score.
Classification Output Example

Object Detection Output & Confidence
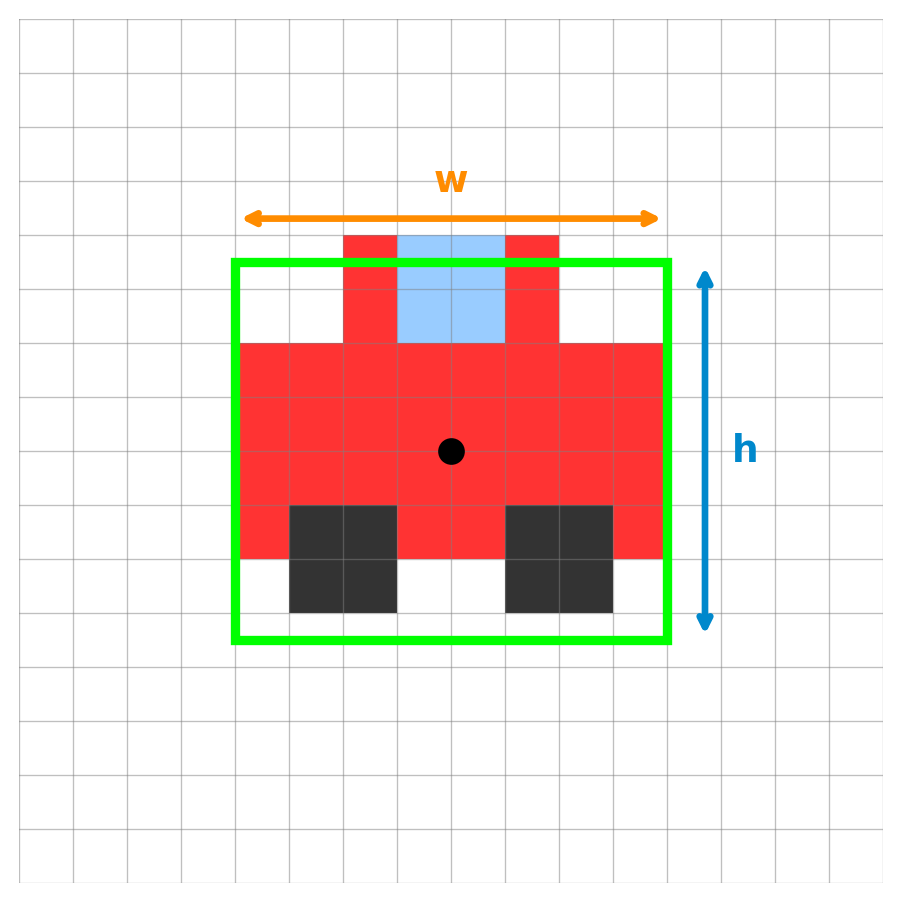
Model Output:
cx, cy(7.5, 7.5): The center coordinates.w(8.0) &h(7.0): The box width and height.conf(0.85): The confidence score.cls(0): The class ID.
Mapping to Bounding Boxes
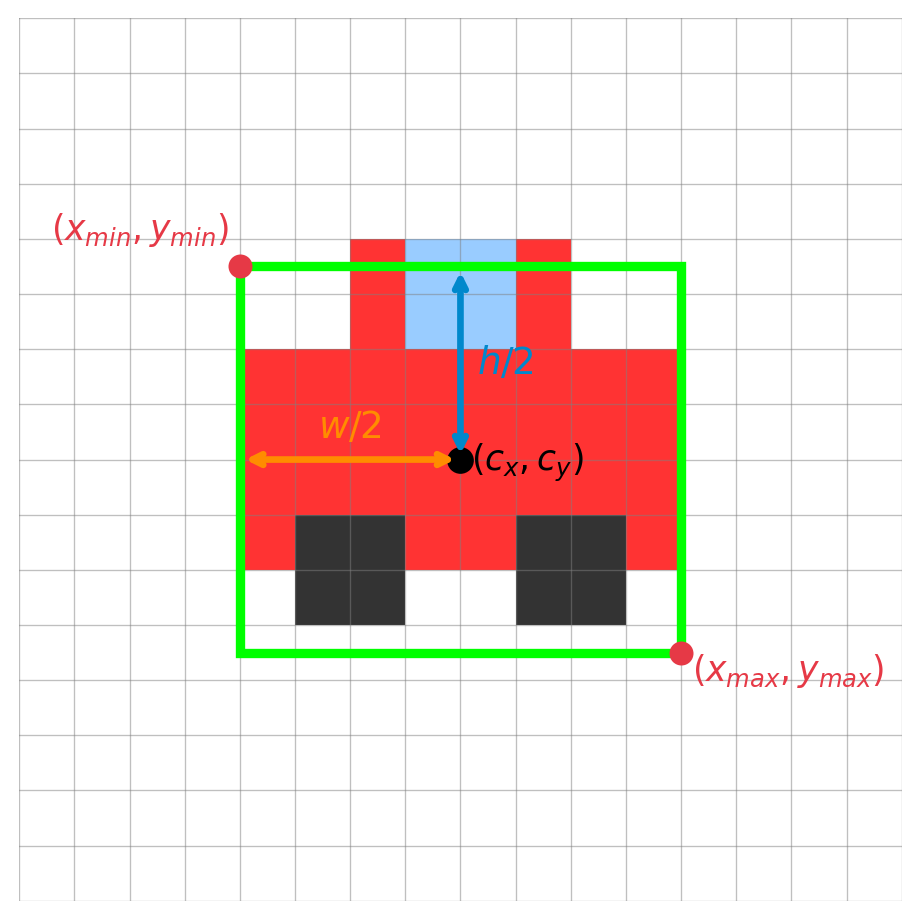
Mapping to \((x_{min}, y_{min}, x_{max}, y_{max})\):
\[ \begin{align*} x_{min} &= cx - \frac{w}{2} = 7.5 - 4.0 = 3.5 \\ y_{min} &= cy - \frac{h}{2} = 7.5 - 3.5 = 4.0 \\ x_{max} &= cx + \frac{w}{2} = 7.5 + 4.0 = 11.5 \\ y_{max} &= cy + \frac{h}{2} = 7.5 + 3.5 = 11.0 \end{align*} \]
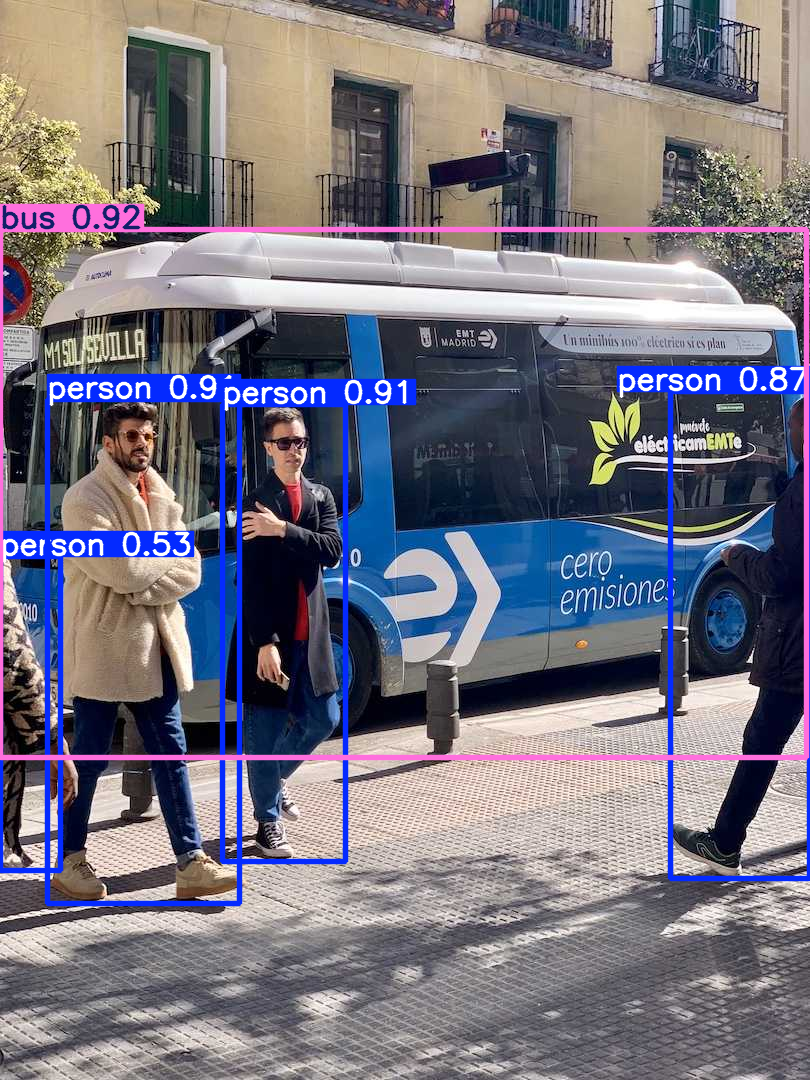
Detection Output Example
The Problem with Absolute Pixels
Why not just train the model on absolute pixel values like w = 8.0?


- Images come in all shapes and sizes (4K, 1080p, square, portrait).
- A car that is
800pixels wide in a 4K image might only be200pixels wide in a 1080p image. - If the model learns “cars are 800 pixels wide”, it will fail on smaller images!
OBB (Oriented Bounding Box) Output Concept
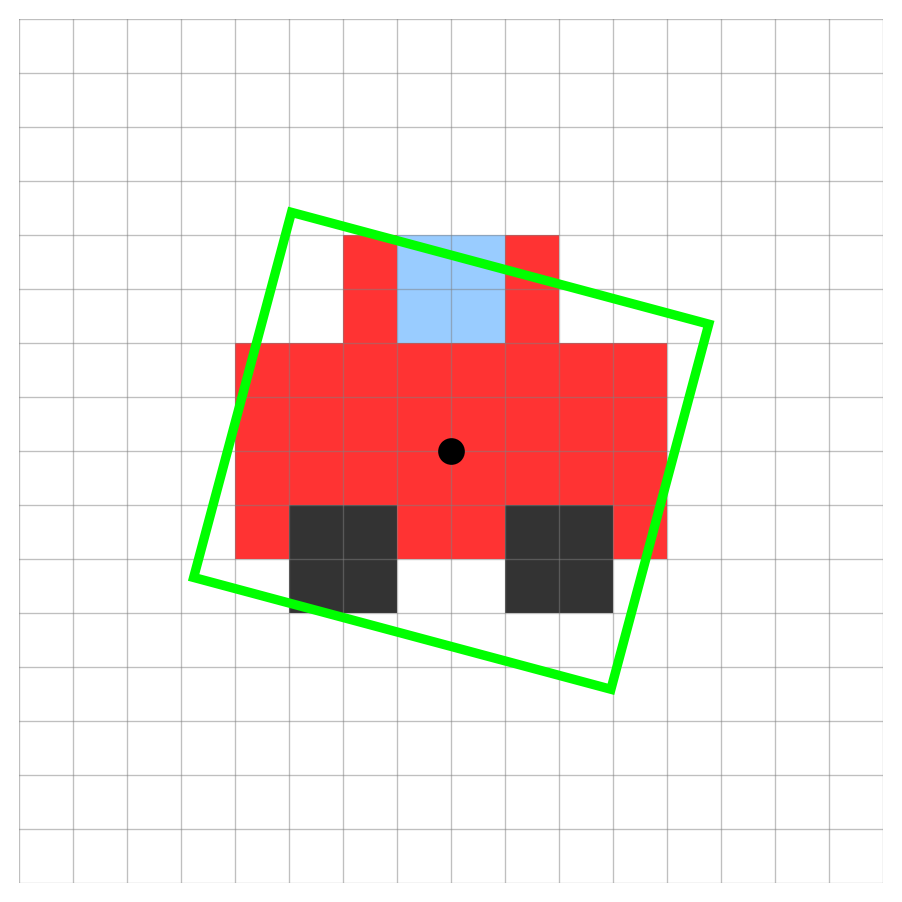
Model Output (Oriented Box):
cx, cy: The center coordinates.w&h: The box width and height.angle: The rotation angle of the box.conf: The confidence score.cls: The class ID.
OBB Output Example

Instance Segmentation Output Concept
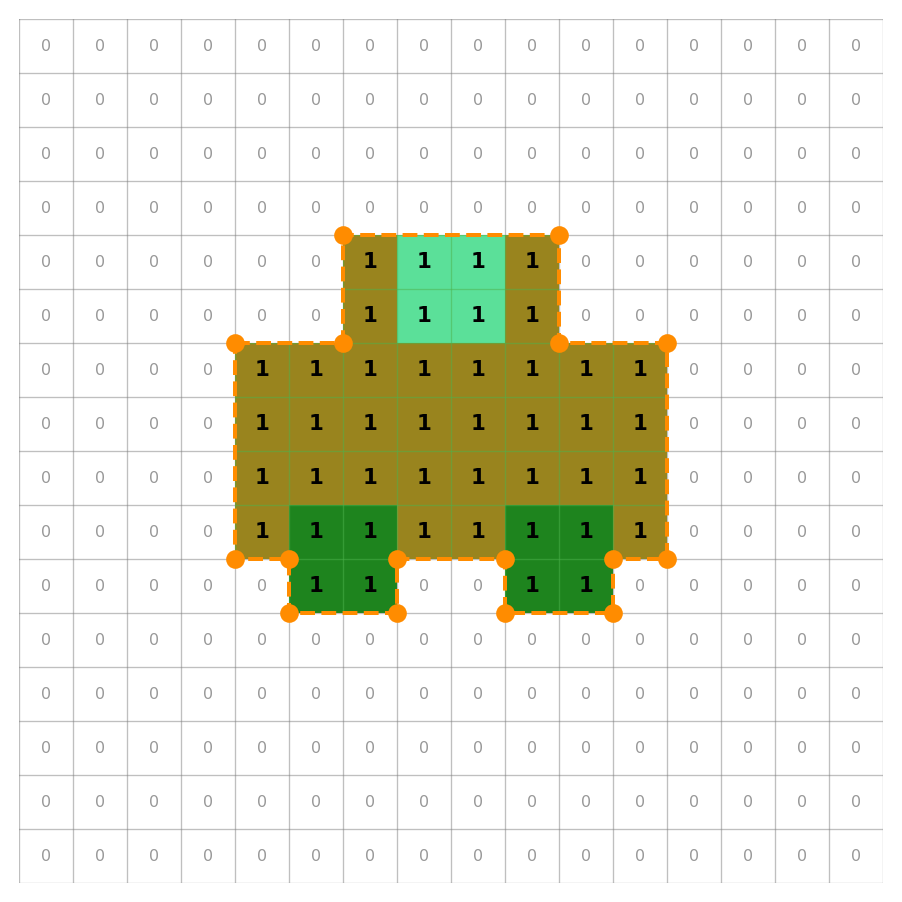
Model Output (Mask / Polygon):
- Mask Tensor: A 2D array (bitmap) of pixels indicating the object’s exact shape (
1= object,0= background). - Coordinates: Sequence of \((x, y)\) polygon coordinates derived from the mask.
conf(0.89): Confidence score.cls(0): Class ID.
Segmentation Output Example

Pose Estimation Output Concept
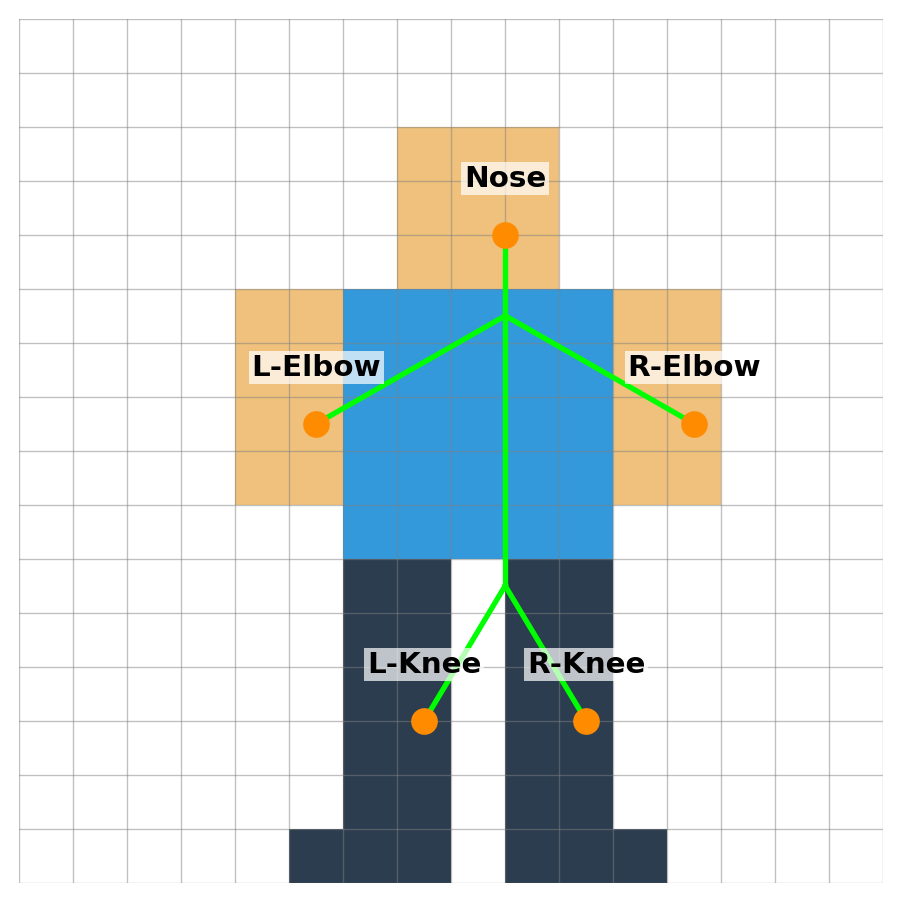
Model Output (Keypoints):
x, y: Coordinate pair for each predefined keypoint.kp_conf(per keypoint): Confidence score for each keypoint’s location.conf(0.92): Overall person detection confidence score.cls(0): Class ID (always 0 = person for pose models).
Pose Estimation Output Example

SAHI: Sliced Aided Hyper Inference
Problem: Tiny objects in high-res images (e.g., 4K) often vanish when resized to 640px.
Solution — SAHI:
- Slice the large image into small, overlapping tiles.
- Run YOLO on each tile at full resolution.
- Merge all detections back together automatically.

