graph LR
A["🔤 Statistical LMs<br/>(N-Grams)<br/>Predict by frequency"]
style A fill:#9B8EC0,stroke:#1C355E,color:#fff
Generative AI Fundamentals
Architecture Fundamentals — Session 1
2026-04-26
What is Generative AI?
Before we build with it — let’s define it.
Generative AI in One Sentence
AI that generates new content — text, images, code, audio — by learning patterns from existing data.
It doesn’t retrieve. It doesn’t look things up. It generates.
The Key Distinction
A search engine finds content that already exists. A generative model creates content that may have never existed before.
What Can It Generate?
Text
- Answers, summaries, essays
- Code in any language
- Translations, rewrites
Images
- Photos, illustrations, diagrams
- UI mockups, product designs
Audio & Video
- Voice synthesis, music
- Video generation
Structured data
- JSON, SQL, tables
- Function calls, tool outputs
This Course
We focus on text generation — the foundation of every AI agent, chatbot, and assistant you’ll build.
Agenda
- A. From Words to Intelligence — the evolution that made GenAI possible
- B. The ChatGPT Revolution — SFT turned completers into assistants
- C. In-Context Learning — no retraining, just better prompts
- D. Thinking Models — from CoT to o1 and beyond
- E. Under the Hood — tokens, probability, sampling controls, and what goes wrong
- F. Key Intuitions — what you know, what’s next
A. From Words to Intelligence
A conceptual tour of the most important ideas.
It Started with Word Completion
The original goal was simple: predict the next word.
Statistical Language Models (N-Grams)
*“The capital of Saudi Arabia is ___“*
- Riyadh (99.8%) ✅ - Jeddah (0.1%) - Paris (0.00001%)
The model looked at the words before it and counted: what word most often follows “capital of Saudi Arabia is” in our corpus?
The Model as a Function
Think of it this way, based on the data we have (corpus), the model is just a function:
\[f(\text{sentence}) = \frac{\text{count}(\text{sentence} + \text{next_word})}{\text{count}(\text{sentence})}\]
Input: a sentence. Output: the most likely next word based purely on counting.
The question became: can we build a better function — one that understands words, not just counts them?
Evolution: Step 1 — Word Completion
The machine learned to finish sentences — nothing more.
Generating a Full Sentence
One word at a time. Step by step.
Prompt: “The sky is”
Step 1 → "The sky is" ➜ blue
Step 2 → "The sky is blue" ➜ and
Step 3 → "The sky is blue and" ➜ clear
Step 4 → "The sky is blue and clear" ➜ [Finished] 🛑
Words Got Meaning — Neural LMs
Remember our function \(f(\text{sentence}) \rightarrow \text{next_word}\)?
A neural network learned to represent words as vectors — coordinates in a space where meaning is geometry, not counting.
Same Function, Better Implementation
Statistical LMs: \(f\) = count frequencies → pick the most common next word
Neural LMs: \(f\) = understand meaning → pick the word that makes sense next
Why Vectors?
When words are coordinates, similarity becomes distance.
- “king” and “queen” land near each other
- The Arabic and English words for “house” are neighbors
- Cross-lingual translation emerged naturally, the model operates on meaning, not spelling
Coming up in the RAG module
We’ll dive deep into how these vectors work — and how we use them to build retrieval systems.
Evolution: Step 2 — Meaning Enters
graph LR
A["🔤 Statistical LMs<br/>(N-Grams)<br/>Predict by frequency"] --> B["🧠 Neural LMs<br/>Words as vectors<br/>Predict by meaning"]
style A fill:#9B8EC0,stroke:#1C355E,color:#fff
style B fill:#00C9A7,stroke:#1C355E,color:#fff
Same task. Richer representation. The machine finally understood relationships between words.
The Architecture Shift: Transformers (2017)
Before 2017, models read text sequentially — word by word, left to right. (LSTMs)
The Transformer (“Attention is All You Need”, Google 2017) changed everything:
- Parallel processing: Read the entire document at once
- Self-Attention: Every word looks at every other word to find relevance
- Eliminated the bottleneck: Now we could finally train on internet-scale data
Why It Mattered
This is the “engine” inside every modern model — GPT, Claude, Gemini, Llama. Without it, scale was impossible.
The Scale Breakthrough — GPT & LLMs (2018–2020)
Once we had the Transformer, we just needed to scale it up.
- GPT-1 (2018) proved it worked.
- GPT-2 (2019) proved it could write believable essays.
- GPT-3 (2020) proved that Scale is a quality of its own.
| Model | Year | Parameters |
|---|---|---|
| GPT-1 | 2018 | 117M |
| GPT-2 | 2019 | 1.5B |
| GPT-3 | 2020 | 175B |
The Revelation
At 175B parameters, GPT-3 could translate, summarize, write code, and answer questions — without being explicitly trained for any of them.
Evolution: Step 3 — Scale Changed Everything
graph LR
A["🔤 Statistical LMs<br/>(N-Grams)"] --> B["🧠 Neural LMs<br/>Words as Vectors"]
B --> T["⚡ Transformers<br/>(2017)<br/>Parallel Attention"]
T --> C["🚀 LLMs / GPT<br/>(2018–2020)<br/>Scale + Emergence"]
style A fill:#9B8EC0,stroke:#1C355E,color:#fff
style B fill:#00C9A7,stroke:#1C355E,color:#fff
style T fill:#FFCC33,stroke:#1C355E,color:#333
style C fill:#FF7A5C,stroke:#1C355E,color:#fff
The task never changed. The scale did — and scale changed everything.
Completion as a Superpower
One mechanism. Many applications.
| Prompt prefix | What the model does |
|---|---|
"Once upon a time" |
Continues as a story |
"Translate to Arabic: Hello → " |
Completes the translation |
"# Python function that reverses a string\ndef reverse(" |
Writes the code body |
The Key Insight
Translation, summarization, and coding are all completion problems in disguise. The model doesn’t switch modes — it just completes the pattern.
Evolution: The Full Picture So Far
graph LR
A["🔤 Statistical LMs<br/>(N-Grams)"] --> B["🧠 Neural LMs<br/>Words as Vectors"]
B --> T["⚡ Transformers<br/>2017"]
T --> C["🚀 LLMs<br/>2020"]
C --> D["💬 ChatGPT<br/>(2022)<br/>Instruction-following<br/>(coming up next)"]
style A fill:#9B8EC0,stroke:#1C355E,color:#fff
style B fill:#00C9A7,stroke:#1C355E,color:#fff
style T fill:#FFCC33,stroke:#1C355E,color:#333
style C fill:#FF7A5C,stroke:#1C355E,color:#fff
style D fill:#1C355E,stroke:#00C9A7,color:#fff,stroke-dasharray: 5 5
(Dashed = foreshadowed — we’ll complete this story in Section B)
B. The ChatGPT Revolution
How SFT turned completers into assistants
The Problem with Raw Completers
Base GPT-2: “Write me a poem”
Write me a poem about the weather
in a different language. Write me a
poem about the weather in a...It continues the sentence. It doesn’t understand you issued a command.
ChatGPT: “Write me a poem”
Here's a poem for you:
The morning light breaks soft and low,
Across the hills where rivers flow...It treats your text as an instruction and responds accordingly.
What changed?
Not the underlying completion mechanism — the training data and process.
Supervised Fine-Tuning (SFT)
Human annotators wrote thousands of correct instruction-following responses. The model was then trained to mimic them.
[Prompt] → "Summarize this article in 3 bullet points."
[Response] → "• Point 1\n• Point 2\n• Point 3"
[Prompt] → "Translate 'Good morning' to French."
[Response] → "Bonjour"The model learned a new pattern: prompts are commands, not text to continue.
Still completion under the hood
SFT didn’t change the architecture. It changed what the model learned to complete — now it completes helpful assistant responses.
RLHF in 30 Seconds
After SFT, a second step aligned the model with human preferences:
- Generate multiple responses to the same prompt
- Human rankers pick which response is better
- Train a reward model on those preferences
- Use the reward model to further tune the base model
One-sentence intuition
RLHF is how we teach the model to prefer helpful and honest completions over merely plausible ones.
The Model Spectrum
graph LR
A["Base Model<br/>(raw completion)"] --> B["Instruction-Tuned<br/>(follows commands)"]
B --> C["Chat-Optimized<br/>(multi-turn dialogue)"]
style A fill:#9B8EC0,stroke:#1C355E,color:#fff
style B fill:#00C9A7,stroke:#1C355E,color:#fff
style C fill:#FF7A5C,stroke:#1C355E,color:#fff
Each step is an evolutionary refinement — same foundation, more alignment.
Evolution: The Full Picture (Updated)
graph LR
A["🔤 Statistical LMs<br/>(N-Grams)"] --> B["🧠 Neural LMs<br/>Words as Vectors"]
B --> T["⚡ Transformers<br/>2017"]
T --> C["🚀 LLMs<br/>2020"]
C --> D["💬 ChatGPT<br/>(2022)<br/>SFT + RLHF<br/>Instruction-following"]
style A fill:#9B8EC0,stroke:#1C355E,color:#fff
style B fill:#00C9A7,stroke:#1C355E,color:#fff
style T fill:#FFCC33,stroke:#1C355E,color:#333
style C fill:#FF7A5C,stroke:#1C355E,color:#fff
style D fill:#1C355E,stroke:#00C9A7,color:#fff
The dashed node is now complete. We have a full completer → assistant pipeline.
C. In-Context Learning
No retraining required — just better prompts
The Insight That Changed Everything
You don’t need to retrain the model. Just show it examples in the prompt.
GPT-3 (2020) demonstrated that a large enough model could adapt to a new task from a handful of examples — with no gradient updates, no fine-tuning, no cost.
This was called In-Context Learning (ICL), and it unlocked prompt engineering as a discipline.
Zero-Shot vs Few-Shot
Zero-Shot
Classify the sentiment:
"The service was terrible."
Sentiment:Model output: Negative
Works for simple, well-defined tasks.
Few-Shot
"Great product!" → Positive
"Terrible service." → Negative
"It was okay." → Neutral
"Absolutely loved it!" →Model output: Positive
Works for nuanced or custom formats.
Rule of thumb
When zero-shot gives inconsistent results, add 2–3 examples. That’s usually enough.
System Prompts as Configuration
The system prompt is the personality dial — it shapes every response without the user seeing it.
Change the system prompt → change the model’s persona, tone, and constraints. No retraining needed.
Prompt Engineering as a Skill
Four levers you control
- Role assignment — “You are an expert in…”
- Structured format — JSON, markdown, bullet points
- Output constraints — “Respond in under 100 words”
- Examples — 2–3 in-context demonstrations
D. Thinking Models
From chain of thought to o1 and beyond
“Let’s Think Step by Step”
In 2022, researchers discovered a single phrase nearly doubled accuracy on math benchmarks:
Direct answer
Q: I have 10 riyals.
I buy 2 coffees for 3 riyals each.
How much money is left?
A: 7 riyalsWrong. (The model guessed.)
With Chain of Thought
Q: I have 10 riyals.
I buy 2 coffees for 3 riyals each.
How much money is left?
Let's think step by step.
A: 2 coffees × 3 riyals = 6.
10 - 6 = 4 riyals.Correct — and verifiable.
Why It Works
Forcing the model to generate intermediate steps means:
- More tokens generated before the final answer
- More “computation” applied to the problem
- Each step constrains what the next step can plausibly be
Intuition
The model doesn’t think before it writes — it thinks by writing. More tokens = more thinking.
The Thinking Model Era
graph LR
A["Chain of Thought<br/>(2022, prompt trick)"] --> B["o1<br/>(2024, trained CoT)"]
B --> C["DeepSeek-R1<br/>(2025, open weights)"]
C --> D["Claude Extended<br/>Thinking (2025)"]
style A fill:#9B8EC0,stroke:#1C355E,color:#fff
style B fill:#00C9A7,stroke:#1C355E,color:#fff
style C fill:#FF7A5C,stroke:#1C355E,color:#fff
style D fill:#1C355E,stroke:#1C355E,color:#fff
The shift: from prompting a model to think step-by-step, to training a model that reasons internally before responding.
The Trade-off
| Standard Model | Thinking Model | |
|---|---|---|
| Response time | ~1 second | ~15–30 seconds |
| Cost | Low | 3–10× higher |
| Best for | Chat, summarization, extraction | Math, coding, complex reasoning |
| Failure mode | Hallucination | Overthinking simple tasks |
When to use thinking models
Use them when correctness matters more than speed — audit tasks, code generation, structured data extraction. Don’t use them for real-time chat.
Evolution: The Complete Story
graph LR
A["🔤 Statistical LMs<br/>(N-Grams)"] --> B["🧠 Neural LMs<br/>Words as Vectors"]
B --> T["⚡ Transformers<br/>(2017)"]
T --> C["🚀 LLMs / GPT<br/>(2020)"]
C --> D["💬 ChatGPT<br/>(2022)"]
D --> E["🤔 Thinking Models<br/>(2024–2025)"]
style A fill:#9B8EC0,stroke:#1C355E,color:#fff
style B fill:#00C9A7,stroke:#1C355E,color:#fff
style T fill:#FFCC33,stroke:#1C355E,color:#333
style C fill:#FF7A5C,stroke:#1C355E,color:#fff
style D fill:#1C355E,stroke:#00C9A7,color:#fff
style E fill:#9B4DCA,stroke:#1C355E,color:#fff
From counting words to reasoning step-by-step — one continuous thread.
E. Under the Hood
The mechanics behind what you’ve been using all session
The Atomic Unit: Tokens
The machine doesn’t actually see “words.” It sees Tokens.
- What are they? Fragments of words — sometimes parts of a word, sometimes a whole word.
- Why? It’s more efficient than having a dictionary of every possible word.
- The Result: The model can read and write words it has never seen before by combining fragments.
Rule of Thumb
1,000 tokens ≈ 750 words. When you’re billed for “input and output,” you’re paying for these atomic fragments.
Tokens in Action: The Stop Token
Remember the generation loop? In modern LLMs, the model doesn’t predict “finished” — it predicts a specific Stop Token.
Step 4 → "The sky is blue and clear" ➜ <EOS> 🛑
The Stop Token
<EOS> (End of Sequence) is a special token in the vocabulary. When the model picks it, generation halts. Without it, the model would keep predicting forever. Every sentence you’ve ever received from an LLM ended because of this token.
The Greedy Problem: Always Picking the Top Word
What if the model always chose the highest-probability word?
Prompt: “Tell me a joke.”
| Run | Response |
|---|---|
| 1st | “Why did the chicken cross the road? To get to the other side.” |
| 2nd | “Why did the chicken cross the road? To get to the other side.” |
| 3rd | “Why did the chicken cross the road? To get to the other side.” |
The Problem
This is called greedy decoding. The model becomes a broken record — deterministic, robotic, and utterly predictable. Every identical prompt returns the exact same output forever.
We need randomness — but controlled randomness.
The Probability Distribution
The model doesn’t “know” facts; it calculates probabilities.
“According to Article 214 of …”
- The (45%)
- Foreign (30%)
- Capital (15%)
- Unicorn (0.01%)
The Decision
It doesn’t always pick the top token. We use Sampling Parameters to control how it chooses from this list.
Sampling: A Bag of Balls 🎱
Think of every word as a colored ball placed in a bag.
The number of copies of each ball is proportional to its probability:
“According to Article 214 of the…”
| Token | Probability | Balls in the Bag |
|---|---|---|
| The | 45% | 🔵🔵🔵🔵🔵🔵🔵🔵🔵 (45 balls) |
| Foreign | 30% | 🟢🟢🟢🟢🟢🟢 (30 balls) |
| Capital | 15% | 🟡🟡🟡 (15 balls) |
| Unicorn | 0.01% | 🔴 (barely 1 ball) |
The Draw
We pull out one ball at random.
- You’ll usually get “The” — but not always.
- “Foreign” has a real chance.
- “Unicorn”? Almost never.
Sampling parameters change how many balls each word gets — that’s all Temperature, Top-K, and Top-P are doing.
Temperature: The “Creativity” Dial
Temperature adjusts the shape of that probability curve.
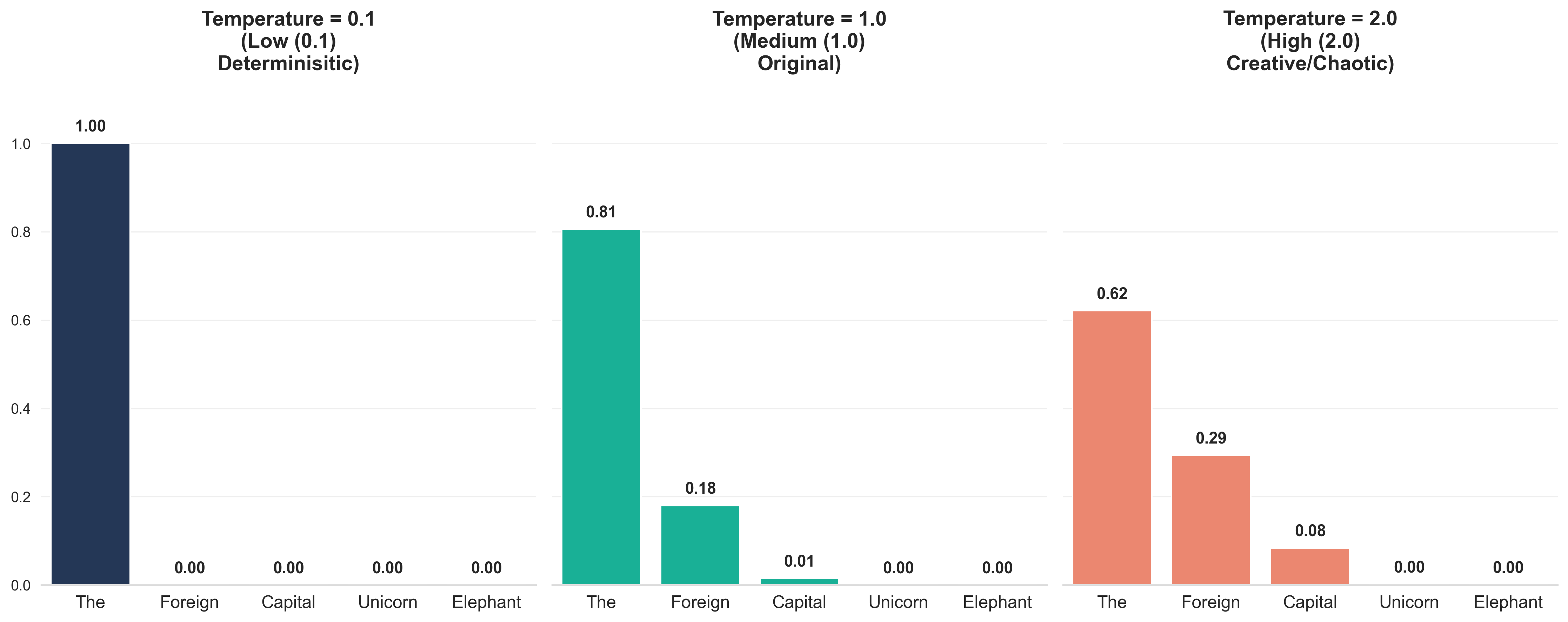
Low Temp (< 0.5) - Sharpened probabilities
High Temp (> 0.8) - Flattened probabilities
Top-K: The “Shortlist”
Top-K simply chops off the list after \(K\) items.
“According to Article 214…”
- The (45%)
- Foreign (30%)
- Capital (15%) – Cut off (if K=2)
- Unicorn (0.01%) – Cut off
Impact
Here, setting \(K=2\) forces it to stick to the very most likely words, preventing weird deviations like “Unicorn”.
Top-P (Nucleus): The “Smart” Cutoff
Top-P sums up probabilities until it hits \(P\) (e.g., 0.9).
Scenario A: The Law (Ambiguous)
- The (45%) + Foreign (30%) + Capital (15%) = 90%
- Result: All three are kept.
Scenario B: The Capital (Certain)
“The capital of Saudi Arabia is…”
- Riyadh (99.8%)
- Result: Hit 90% immediately. Stops there.
Why Top-P wins
It adapts to the context. It’s strict when the answer is clear (Riyadh), and flexible when it’s open-ended or we have synonyms.
Cheat Sheet: Configuration
| Parameter | Effect | Recommended Value |
|---|---|---|
| Temperature | Randomness | 0.0 (Fact/Code) – 0.7 (Chat) – 1.0 (Creative) |
| Top-P | Dynamic vocabulary | 0.9 (Standard), 1.0 (Disable) |
| Top-K | Hard vocabulary limit | 40-100 (Standard) |
Best Practice
Usually, you tune Temperature and Top-P. Leave Top-K alone or at default.
Hallucinations: When Guessing Fails
Hallucinations are structural. They aren’t a bug; they are the result of the model doing its job without enough context.
- Probability over Truth — It picks statistically likely words, not verified facts.
- Plausibility over Accuracy — It is trained to sound correct, which makes its lies dangerous.
- Training Gaps — If it hasn’t seen the “Saudi Investment Law,” it will confidently invent one that sounds legal.
Production Risk
A hallucinating chatbot creates real legal and financial liability. “Confident, fluent lies” are harder to spot than obvious errors.
Mitigation Strategies
| Strategy | How It Works | When to Use |
|---|---|---|
| RAG | Ground responses in retrieved documents | Most enterprise apps (Module 04) |
| Output Validation | Verify against structured data/rules | Factual claims, numbers |
| Temp = 0 | Force the most likely (factual) path | extraction, classification |
| Human-in-the-Loop | Human review before action | Critical decisions |
The Core Lesson
The same mechanism that writes a creative novel also writes a confident lie. Control the mechanism, or provide the data.
F. Key Intuitions
What you know and what’s next
Key Takeaways
- GenAI generates, not retrieves — it creates content by predicting what comes next, at scale.
- Completion is the primitive — translation, coding, and conversation all reduce to next-word prediction.
- Scale created emergence — GPT-3 wasn’t programmed to translate; it learned translation as a side effect of predicting text at 175B parameters.
- Hallucinations are structural — the model generates plausible text, not true text. Always plan a mitigation strategy.
- SFT aligned completers — ChatGPT didn’t invent a new architecture; it trained the model to treat prompts as commands.
- In-context learning — you can adapt a model to new tasks in real time, just by showing examples in the prompt.
- Thinking models trade speed for accuracy — chain of thought and o1-style reasoning give you better answers at higher cost and latency.
What We Intentionally Skipped
This session focused on intuition. We deliberately left out:
| Skipped | Why | When you’ll need it |
|---|---|---|
| Transformer architecture | You don’t need it to build | Academic curiosity only |
| Attention math | Same reason | Deep ML research |
| KV-cache mechanics | Not relevant yet | Session 2 — it affects your API bill |
The principle
Understand the behavior of the model before its internals. Once you’re building with the API, the internals become relevant — and we’ll cover them exactly when they matter.
Up Next
Lab 1: Hands-on tokenization and cost analysis — see how tokens, context windows, and costs connect in practice.
